
CoANet: Connectivity Attention Network for Road Extraction From Satellite Imagery
Published in IEEE Transactions on Image Processing (TIP), 2021
Jie Mei1, Rou-Jing Li2, Wang Gao3, Ming-Ming Cheng1
1TKLNDST, CS, Nankai University
2Beijing Normal University
3 Science and Technology on Complex System Control and Intelligent Agent Cooperation Laboratory
Abstract
Extracting roads from satellite imagery is a promising approach to update the dynamic changes of road networks efficiently and timely. However, it is challenging due to the occlusions caused by other objects and the complex traffic environment, the pixel-based methods often generate fragmented roads and fail to predict topological correctness. In this paper, motivated by the road shapes and connections in the graph network, we propose a connectivity attention network (CoANet) to jointly learn the segmentation and pair-wise dependencies. Since the strip convolution is more aligned with the shape of roads, which are long-span, narrow, and distributed continuously. We develop a strip convolution module (SCM) that leverages four strip convolutions to capture long-range context information from different directions and avoid interference from irrelevant regions. Besides, considering the occlusions in road regions caused by buildings and trees, a connectivity attention module (CoA) is proposed to explore the relationship between neighboring pixels. The CoA module incorporates the graphical information and enables the connectivity of roads are better preserved. Extensive experiments on the popular benchmarks (SpaceNet and DeepGlobe datasets) demonstrate that our proposed CoANet establishes new state-of-the-art results.
Method
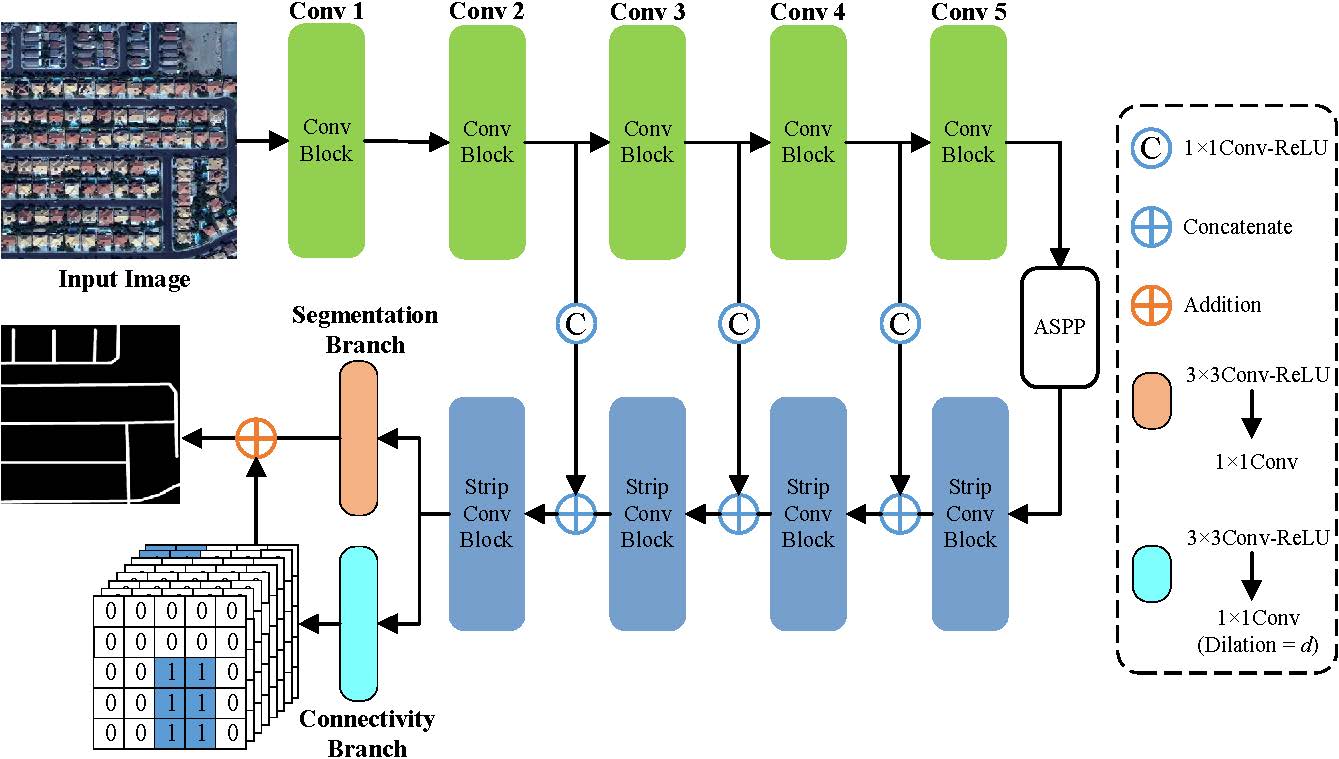
Figure 1. Overall architecture of the proposed connectivity attention network (CoANet). The encoder module contains five convolution blocks. The ASPP is the Atrous Spatial Pyramid Pooling module, which learns multi-scale features by applying atrous convolution with multiple scales. And the decoder module includes four strip convolution blocks. d denotes the interval of a given pixel with its neighboring pixels.
We propose a connectivity attention network (CoANet) for road extraction from satellite imagery. We first introduce an encoder-decoder architecture network to learn the feature of roads, where the Atrous Spatial Pyramid Pooling module (ASPP) is adopted to increase the receptive field of feature points and capture multi-scale features. Since the roads are long-span, narrow, and distributed continuously, the strip convolutions are more aligned with the shapes of roads. We take advantage of it and develop a strip convolution module (SCM), which is placed in the decoder network. The SCM leverages four strip convolutions with horizontal, vertical, left diagonal, and right diagonal to capture long-range context information from four different directions. Besides, it prevents irrelevant regions from interfering with feature learning. To alleviate occlusions in road regions caused by buildings and trees, we propose a connectivity attention module (CoA) to explore the relationship between neighboring pixels. The connectivity of a given pixel with eight neighboring pixels is predicted, which enables the topological correctness of roads.
Code
CoANet: Connectivity Attention Network for Road Extraction from Satellite Imagery, Jie Mei, Rou-Jing Li, Wang Gao, Ming-Ming Cheng, IEEE TIP, 2021. [PDF][Code]
Please contact Jie Mei (meijie AT mail.nankai.edu.cn) for any questions.
Citation
It would be high appreciated if you can cite our paper when using our code:
@article{mei2021coanet,
title={CoANet: Connectivity Attention Network for Road Extraction From Satellite Imagery},
author={Mei, Jie and Li, Rou-Jing and Gao, Wang and Cheng, Ming-Ming},
journal={IEEE Transactions on Image Processing},
volume={30},
pages={8540--8552},
year={2021},
publisher={IEEE}
}